
In NLP, Similarity Matching has several use cases, such as matching resumes with job-listing. In a chatbot, match phrases to find intent, match legal documents for compliance, or map curriculum. This blog generically describes how to build such a solution on the Google Cloud.
At the center of such a solution is an orchestrator. Trillo Workbench plays the role of orchestrator. But you can build your orchestrator. It is just that Trillo Workbench can save you hundreds of thousands of dollars or even millions. It can save time to market as well.
The rest of the article focuses on the technical solution.
Solution Requirement
Given an input document, find the matching in a set of documents provided earlier.
Solution Approach
Index existing documents for search. To index the documents:
- Convert documents into a set of vectors (using text embedding)
- Store vectors in a vector database.
- Convert the input document into a vector.
- Search for the matching vectors in the vector database.
Components of Solution
The above-described solution approach leads to the following components.
- A workflow to convert documents into vectors.
- Vector database and a process to insert/update vectors into the database.
- The last component would be a service for finding matching documents.
The scalability of the solution is of utmost importance. The source documents may be in millions leading to billions of vectors. That is where Google Cloud comes into play.
Architecture and Workflow for Indexing Documents as Vectors
See the numbered steps of the workflow in the diagram below to understand how vectors are generated and indexed.
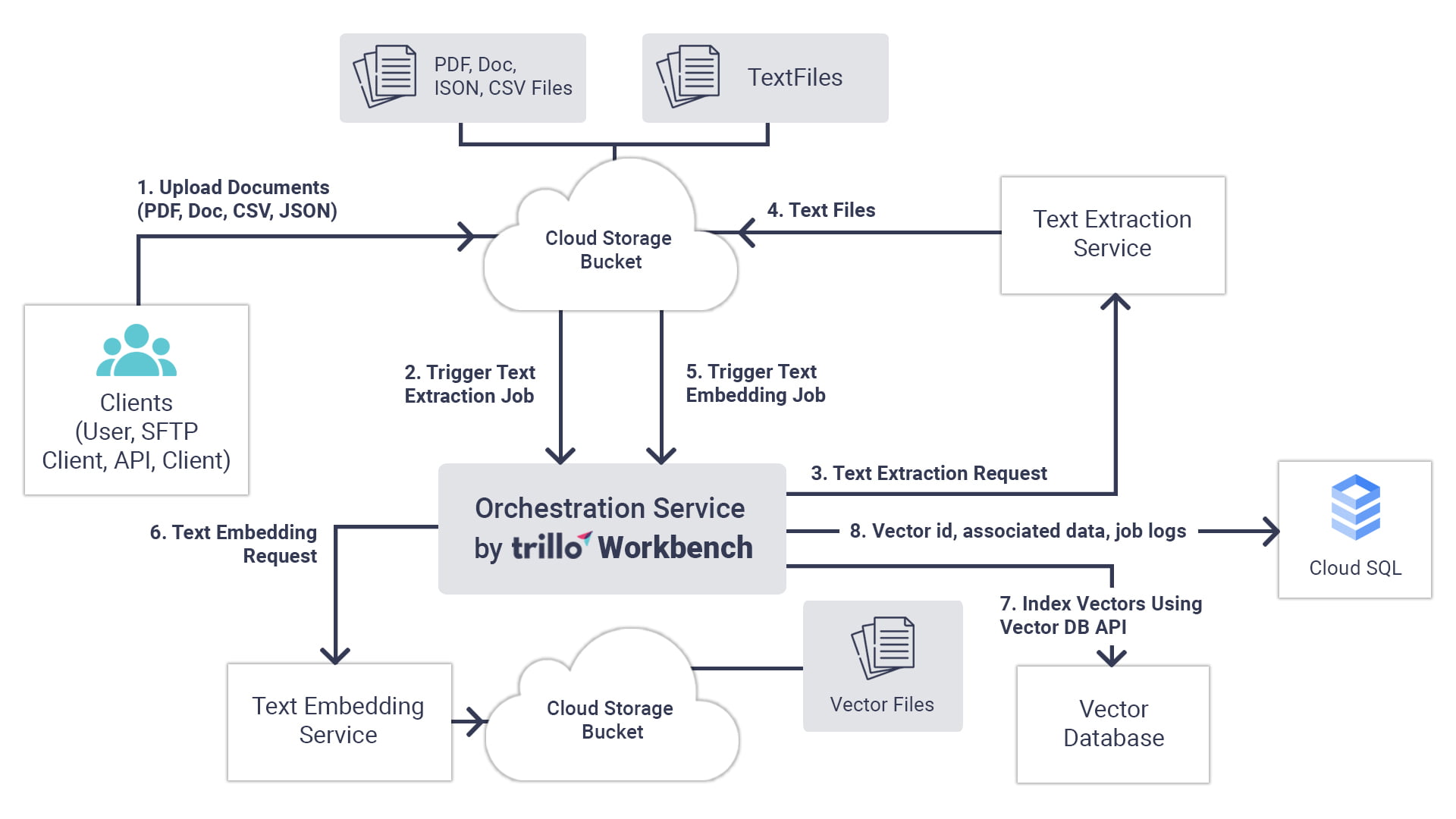
A brief description of the workflow is as follows:
- User uploads a set of documents to cloud bucket (large number 100s of thousands to millions)
- A backend job would extract text from these documents and produce text embeddings (vectors).
- The text embedding files are stored in a bucket.
- Another job indexes text embedding in a vector database.
- In some use cases, each document has additional information. In step 8, such information is stored in Cloud SQL.
- Also, a detailed log, status of each task is stored in the Cloud SQL DB
Service and Workflow for Similarity Matching
Once the vector database of the source documents is ready, use the following workflow to search the matching documents to a given input.

A brief description of the search workflow is as follows:
- A user uploads the document to be matched to a search service.
- Search service extracts text from the input document.
- The text is converted to a vector using a text embedding service.
- The input vector is matched against the vector database.
- Search results are returned back to the client. If there is any associated info with the original document, that is pulled from the CloudSQL and returned with the result.
Text Extraction Service
Trillo Workbench provides text extraction service for several types of documents PDF, Docs, CSV, Excel, Media files, etc.
Text Embedding Service
Depending on the use case, one of the following algorithms is used for text-embedding (converting text to vectors).
- TF-IDF — has a limitation in that it does not provide semantic matching.
- Universal Sentence Encoder (USE) — less compute resource requirements.
- BERT — state of art.
- GPT — state of art.
Vector Database
Since a system will generally have millions to billions of vectors, a scalable and reliable service is needed. Google Matching Engine ANN is an easy-to-use and managed service. There are other commercial services and open source options too (see the reference below)