

Model-Driven Design & Google Cloud SQL for Data as a Service
Firebase provides a declarative framework to build a data layer and publish it as API. It also provides a declarative security model.
A similar declarative approach for Cloud SQL or BigQuery will be useful. Based on the declarative model, a runtime can provide secure and role-based access to the Cloud SQL and many more features that can be useful compliance, performance, scalability, data loss preventions, etc.
Such a declarative approach to building a data layer is also referred to as a Model-Driven Architecture (MDA). In this approach, the model is used to describe the schema, security, access control, audit control, validation, etc. using a meta-model. In essence, a meta-model describes the characteristics of the data. In the relational world, DDL is a model to describe data schema, therefore you can view it as the meta-model. A comprehensive meta-model is the one that abstracts DDL and other features such as security, validation, scalability, concurrency, audit control.
MDA can be overly complex and scary. But by abstracting it and providing a platform, we have simplified it greatly. We have used it for complex data models in transactional and data warehouse kinds of applications.
Components of a Model-Driven Platform
There are two components of a model-driven platform.
- Design Time: This provides a UI or editor for specifying metadata. The metadata per table (or class in the UML terms) is stored in a file. Each file has the name of the class, its table name, columns (attributes), indexing, relationships with other tables, security declarations of each attribute and the table, etc.
- Run Time: A horizontally scalable runtime that can enact the metamodel and bring it to the life. On the cloud, it will be implemented as a set of microservices running on Kubernetes Engine (or GKE on the Google Cloud).
How Developers can use it?
It is simple to use such a platform.
- Specify data model, security model, etc as metadata using UI. Or, introspect data model from an existing database and augment it with the security model, scalability model (caching), etc. Also, define parameterized database queries that can be used as APIs.
- Deploy it on the runtime.
- Access data as a service using restful APIs or using client toolkit for various programming languages such as Java, JavaScript, etc.
Trillo Workbench provides a model-driven implementation for Google Cloud SQL and BigQuery. Trillo Workbench provides several other services not discussed here.
The following screenshots would help visualize how the model-driven approach works for Cloud SQL and BigQuery.
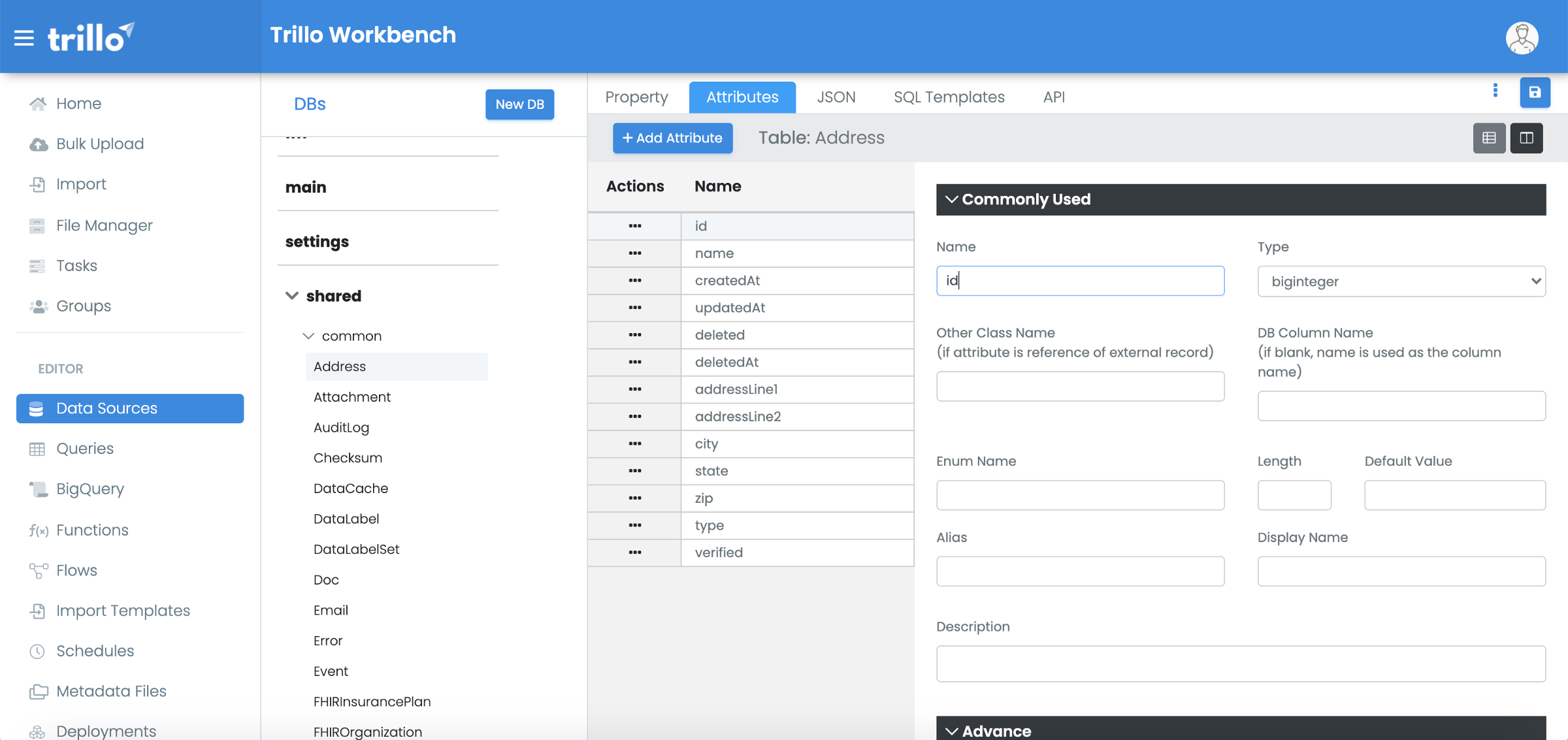
A. Metadata of a Table (or Class)
A table’s schema, security model, etc can be specified using UI or JSON editor.
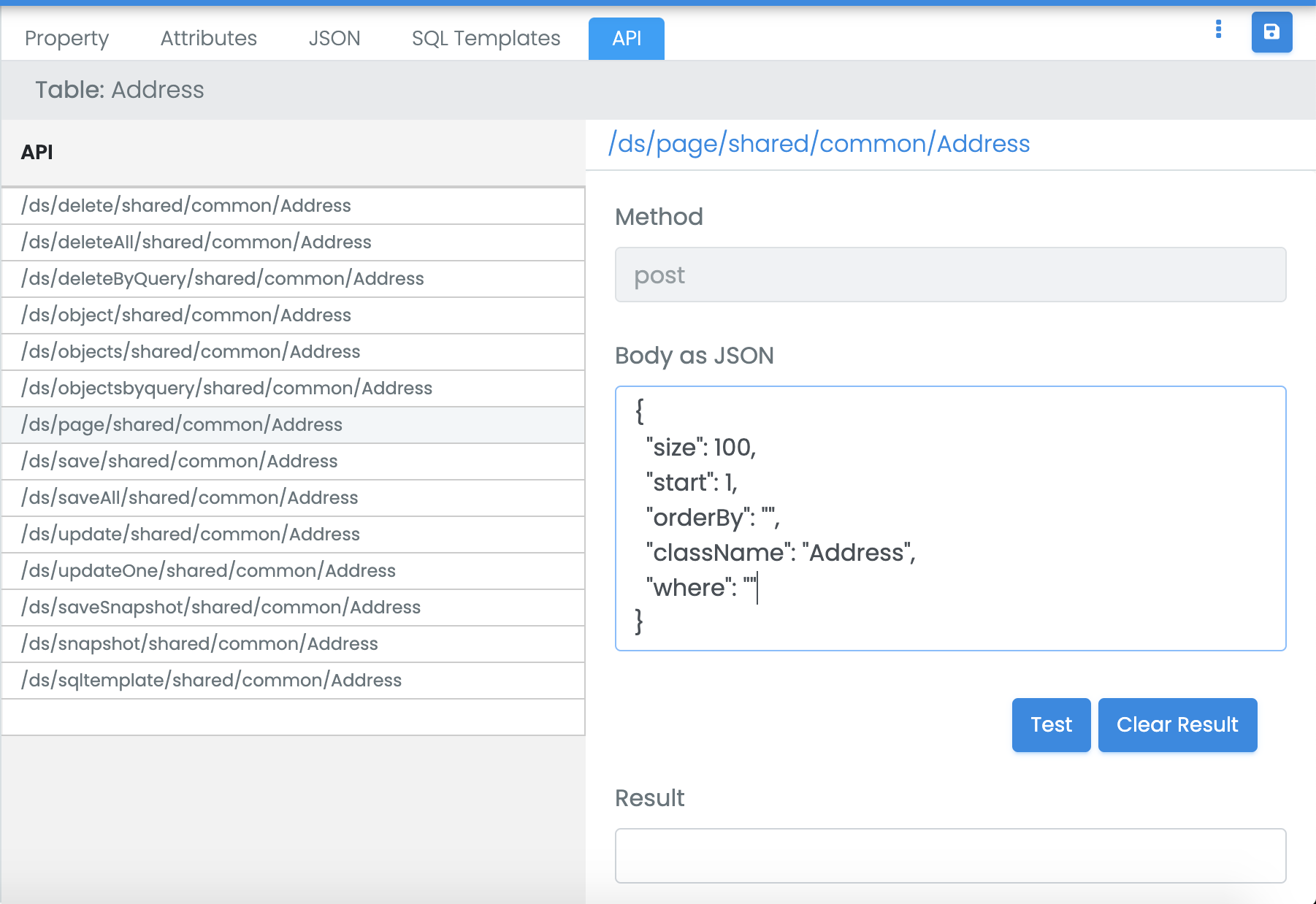
B. Data as API
Once the table is saved, it gets deployed on the top of the development runtime and publishes data as service (the deployment to the staging/production environment is using Git repository).
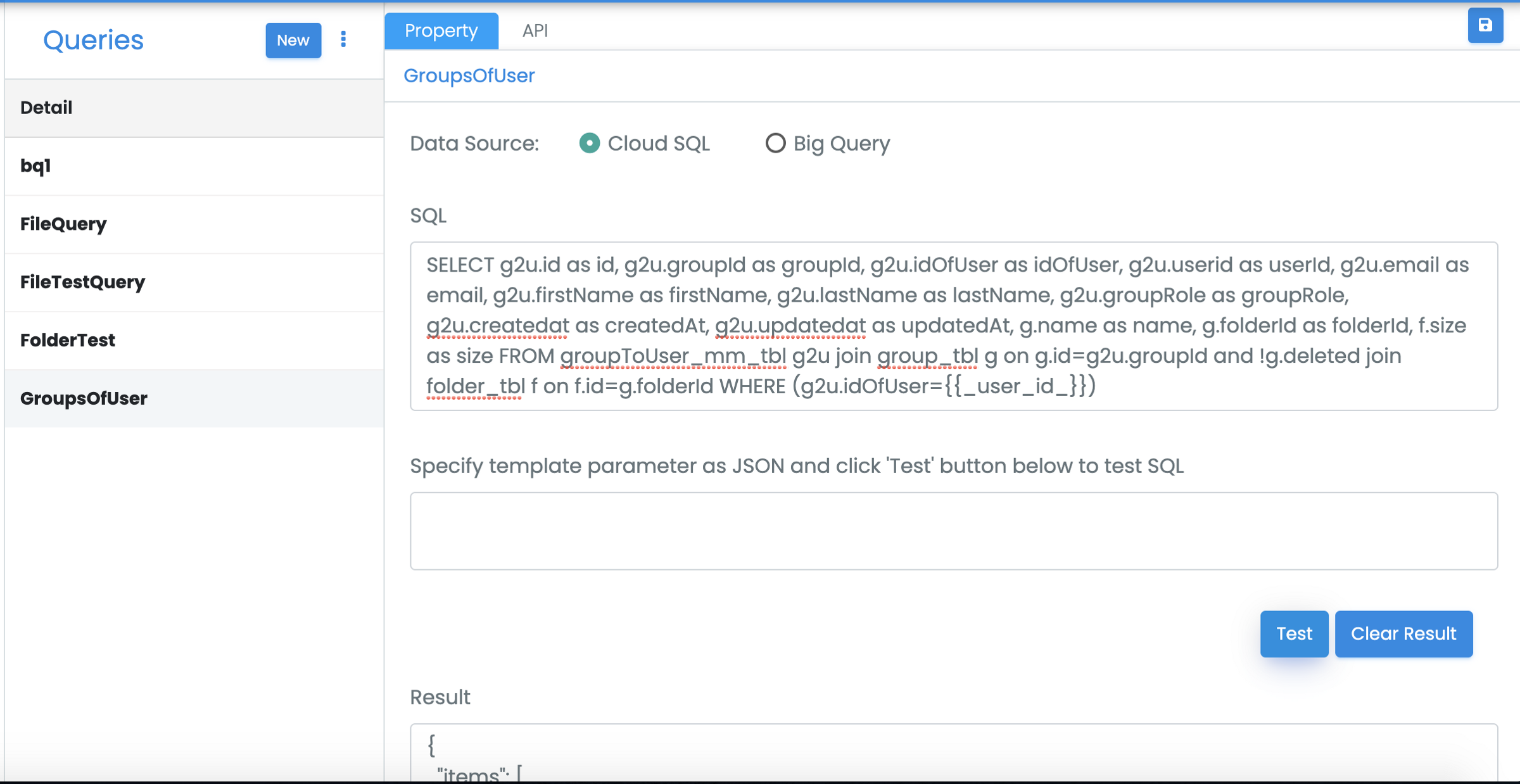
C. Custom Queries as API
Any customer query can be exposed as an API.
D. Using in Code
See the example lines of java code for using accessing and updating data using the client toolkit. Example APIs,
- DSApi.getObject(…) — for a class ‘Run’ defined using metadata, get one record by its ‘id’ (primary key). This API will enforce the security and access control model as specified.
- DSApi.getOneByQuery(…) — gets on an object by the query (for example in the case of one-to-one association.
- DSApi.save(…) — Save an object of type EduReport into DB.

Conclusion
A scalable data layer can be built on top of Cloud SQL and BigQuery using a model-driven approach. It helps deliver a running service at 10X speed, it is agile and robust.